JVM垃圾回收的算法和收集器
作者:binjvm三大垃圾收集算法
jvm常见的垃圾收集器
Serial收集器
新生代、单线程收集器,历史最悠久,使用复制算法,收集时需要暂停用户线程
Serial Old收集器
老年代、单线程收集器,使用标记整理,收集时需要暂停用户线程
ParNew收集器
年轻代、多线程收集器,实际上时Serial的多线程版本,收集时需要暂停用户线程,通常与CMS配合使用,也可以和Serial Old一起用
Parallel Scavenge收集器
新生代、多线程收集器,使用复制算法,Parallel Scavenge关注点是吞吐量,吞吐量=代码运行时间/(代码运行时间+垃圾回收时间),例如代码运行时间是99s,垃圾回收1s,那么吞吐量就是99%
分别是控制最大垃圾收集停顿时间 的-XX:MaxGCPauseMillis参数,以及直接设置吞吐量大小的-XX:GCTimeRatio参数。
Parallel Old收集器
老年代、多线程收集,使用标记整理算法,Parallel Scavenge的老年代版本,
CMS收集器
老年代、多线程收集,使用标记清除算法,CMS关注的是减少暂停用户线程时间,
通常与ParNew一起使用,因为和Parallel Scavenge不兼容。
收集过程
1.初始标记,暂停用户线程,耗时短,并发标记GC root直接关联的节点
2.并发标记,无需暂停,较耗时长,并发标记整个对象图,但是可与用户线程并行
3.重新标记,暂停用户线程,耗时短,修正并发标记期间,出现变动的对象,这个阶段时间比并发标记短很多
4.并发清除,无需暂停,耗时长,并发清除那些标记为垃圾的对象
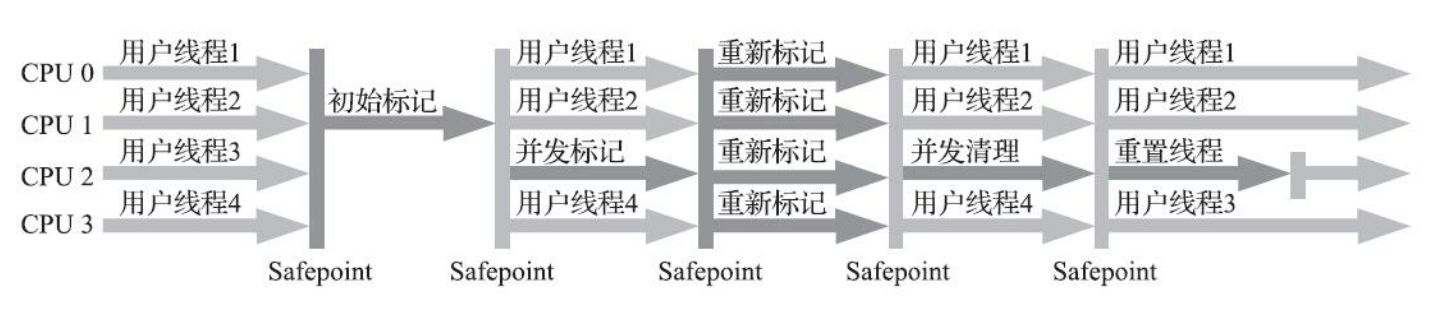
整个收集过程,耗时长的阶段都与用户线程并行,CMS垃圾回收时使用的线程数量 = (CPU核心数 + 3)/4。通常垃圾回收时只占用不超过25%的处理器资源比较合适,核心数比较多的话,这个值会更低,当时核心数低4时,受影响就比较大,如果超过一般,那么会用明显的影响。
关于浮动垃圾
CMS收集器时并发清除的,可能清除时产生新的垃圾,即「浮动垃圾」,CMS浮动垃圾当次收集没办法处理的,必须要等待下一次收集时处理。
由于CMS无法处理「浮动垃圾」,当CMS进行运行期间,如果剩余当空间无法满足新对象的分配需求,就有可能出现「Con-current Mode Failure」导致一次暂停用户线程的Full GC,临时启用Serial Old收集器来对老年代进行收集,我们可以通过
-XX:CMSInitiatingOccupancyFraction
参数来配置触发回收的百分比,默认是占用92%触发。
关于内存碎片
因为CMS是基于标记清除算法实现的垃圾回收器,没有进行压缩整理的过程,那么收集结束时,就会产生大量空间碎片,如果新对象无法分配足够的连续内存空间,那就会触发一次暂停用户线程的Full GC,可以通过
-XX:+UseCMS-CompactAtFullCollection
参数配置,Full GC几次后触发整理过程,默认时0,即每次都触发。
Garbage First收集器
G1是混合收集器(即收集老年代、也收集新生代),多线程收集,G1将java堆划分成连续的region,每个region都可以按需要变长老年代或者新生代。region中还有一个叫Humongous的区域,专门用来存大对象的,一般大于region空间的一般的话,就判定为大对象。region的大小可以通过参数
-XX:G1Heap RegionSize
来配置,可以指定1MB~32MB,并且应该是2的N次幂,如果超过region的对象,就被放在多个连续的Humongous中
关于停顿时间
G1收集器可以通过
-XX:M axGCPauseM illis
来指定收集时间,默认是200ms,因为G1是将堆分成无数个小的region,所以他可以计算出历史收集每个单元的平均时间,根据这个时间,计算限定时间可以回收多少的region,但是这个时间只是做参考,并不一定完全相等,垃圾收集器是尽量往这个时间靠
关于记忆集和卡表
G1收集器因为使用的是region结构,那么就要维护双向的卡表,即A region指向B region的引用,同时也存了B region指向A region的引用,这样的话,卡表就会更占堆空间,按经验是占10%-20%空间。
TAMS
TAMS(Top at Mark Start)的指针,G1会把每个region中画出一个区域,用于新对象的创建,这个区域的边界就是用2个TAMS标记,因为G1是基于原始快照(SATB)算法来实现的,所以在TAMS之间新增的对象,默认不纳入本次回收的范围。
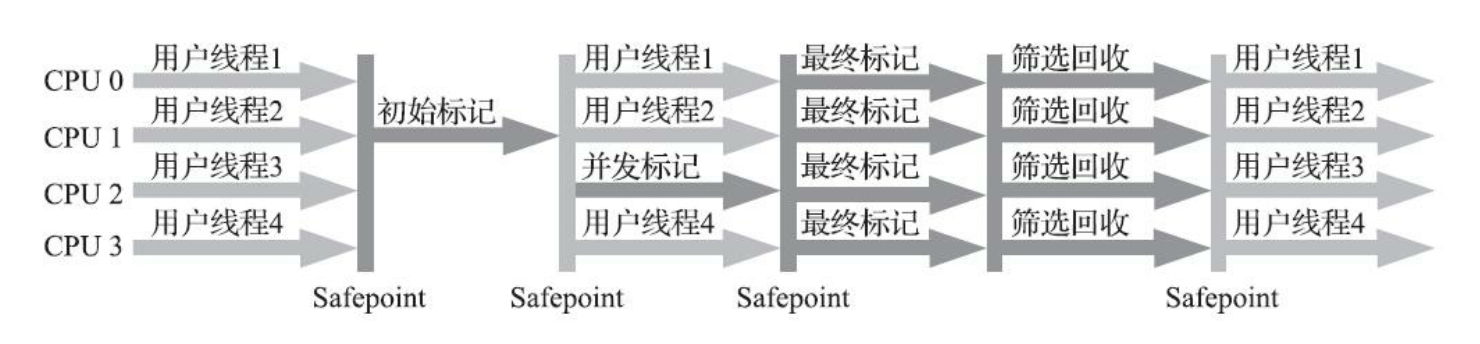
回收的步骤
1.初始标记,耗时短,需暂停用户线程,仅标记GC root直接关联的对象。
2.并发标记,耗时长,无需暂停用户线程,扫描整个对象图,并且处理原理快照(SATB)下引用变动的对象
3.最终标记,耗时短,需暂停用户线程,处理并发阶段仍然遗留的SATB引用变动
4.筛选回收,耗时可控,需暂停用户线程,根据用户配置的期望暂停时间,来制定回收计划,可以回收任意多个region,尽量往配置时间靠
与CMS比较
CMS基于标记清除,而G1整体看是基于标记整理,从region局部看是基于复制算法(2个region之间),G1不会长生内存碎片,并且可以控制停顿时间。
G1的卡表会更加复杂(双向),更占内存,CMS则更简单只需要保存老年代到新生代到即可。
CMS使用增量算法,这样会导致最终标记会暂用更多的时间,G1的原始快照就不会有这个问题。
所以综上来看,
如果java程序是cpu型的,那么可以考虑用G1去做,同时加大内存,例如内存大于6G
如果是内存型的那么用CMS去做,同时增加CPU以提高最终标记的效率。