java对象的内存布局
作者:bin堆中对象堆的存储布局可分为三个部分:对象头(Header)、实例数据(Instance Data)、填充(Padding)
对象头:又包含Mark word、类型指针、数组长度(如果是数组)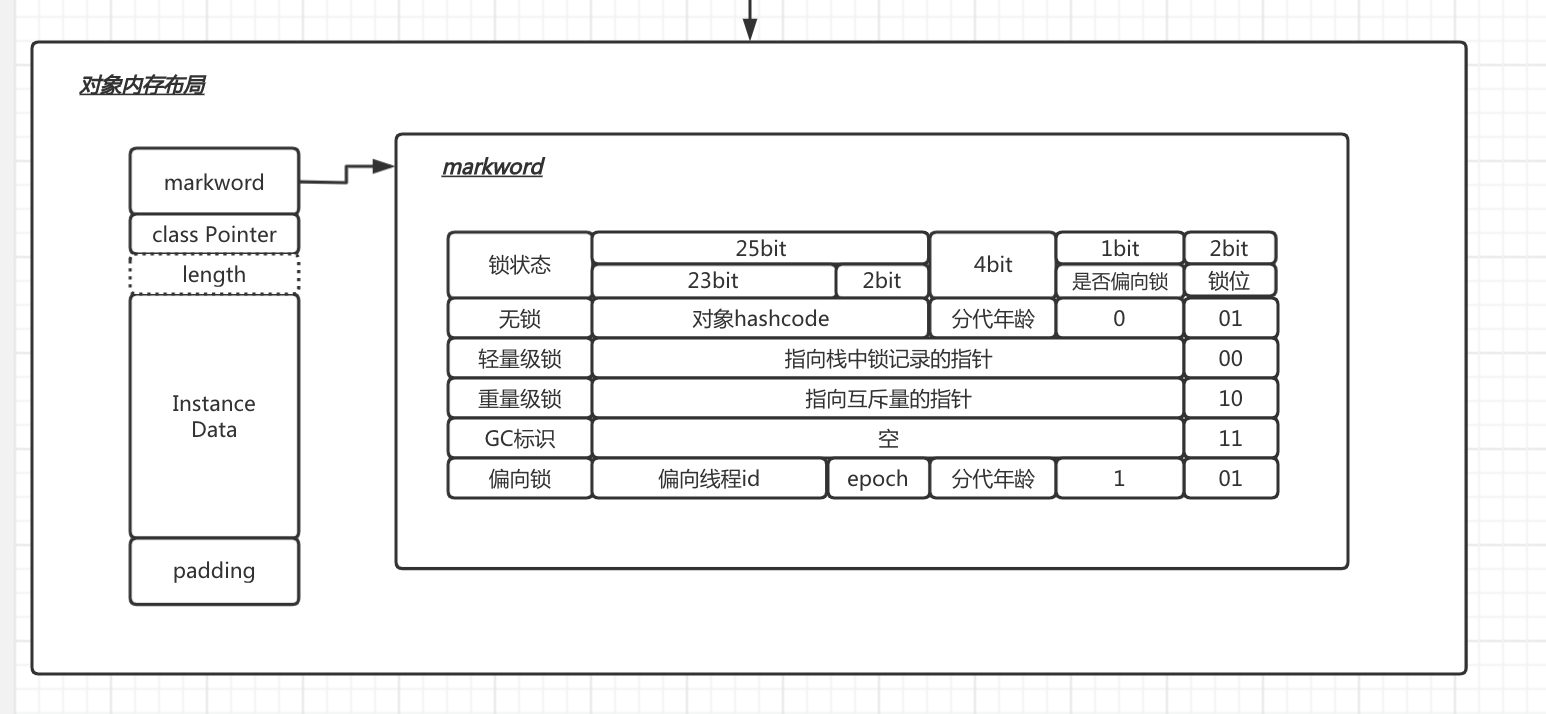
如果是64位虚拟机,默认开启了-XX:+UseCompressedOops,压缩指针,会将64位的markword,压缩称32位。
Mark word
主要存的锁标识、GC回收标识、偏向锁偏向的线程。
值得注意的是,对象无法在无锁和偏向锁状态共存,如果一个对象在计算过identity hash code后,就无法变成偏向锁,如果已经是偏向锁,需要计算identity hash code,就会直接膨胀位重量级锁
重量级锁的实现中,ObjectMonitor类中有地方会存下非加锁状态的mark work,其中就包含类hash code。
其中identity hash code指的是:java.lang.Object.hashCode() 或者 java.lang.System.identityHashCode(Object) 所返回的值
类型指针
指向元数据中存储的类地址
数组长度
如果是数组对象,会在元数据中的类信息确定数组的大小
实例数据(Instance Data)
接下来实例数据部分是对象真正存储的有效信息,即我们在程序代码里面所定义的各种类型的字 段内容,无论是从父类继承下来的,还是在子类中定义的字段都必须记录起来。
填充(Padding)
这部分没有特别意义,就是用于对齐8的倍数。
对齐其中的一个目的是因为计算机的缓存行通常是8的倍数,32或者64,避免同一个对象出现在2个缓存行的情况,那么读取就需要对2个缓存行操作。
虚共享问题
假设2个线程在修改同一个voliate变量,逻辑上他没有共用一个变量,不存在同步逻辑,但是如果存在2个对象同在一个跨缓存行的问题,那么就需要同步执行,影响效率
java8 引入了@Contended,用于解决虚共享问题,被@Contended标识的字段,会独立存储一个缓存行,但也会导致缓存行剩余空间但浪费