MySQL事物原理与MVCC
作者:bin事务隔离级别分为以下4种:
read uncommitted | 读未提交
read committed | 读已提交
repeatable read | 可重复读
serializable | 串行化
从上往下,事务的隔离级别越高,越能保证数据的完整性、一致性,但是对并发性能影响也越大。
- 一、前2种read uncommitted和read committed,主要是针对事务的commit前后关联的
1.前者是可以在A事务中读到B事务commit前到修改(B事务回滚,会导致即A出现了脏读,即A读的数据不是正确的)
2.后者在A事务中读不到B事务commit前的修改,A可以读到B事务commit后到修改(B事务commit前后,A读的数据不一致,即不可重复读,因为重复读不一样)
- 二、repeatable read | 可重复读(mysql默认级别)
可重复读即为了解决上面「一.2」不可重复读读问题,即A事务读到到数据,和B事务是否commit无相关(但是会出现幻读,即A读到的数据不是最新的,因为B事务已经提交commit了)
可重复读,可以理解为每个开启事务读session都在当前db版本的快照下面修改,与其他session不关联。
- 三、serializable | 串行化
即串行话执行事务,事务隔离级别为串行化时,读写数据都会锁住整张表
MySQL事物的实现
事物的特点(ACID):原子性(Atomicity),一致性(Consistency),隔离型(Isolation)以及持久性(Durability)
事物的目的:保证可靠性 + 并发性能
可靠性,innoDB使用redo log、undo log去保证
并发性能,innoDB使用mvcc多版本并发控制,去将读写隔离,提高并发性能
1、redo log
redo log 用于支持事物的持久性(Durability)
redo log 分两部分,redo log buffer 和redo log 文件,先写buffer,再写文件。
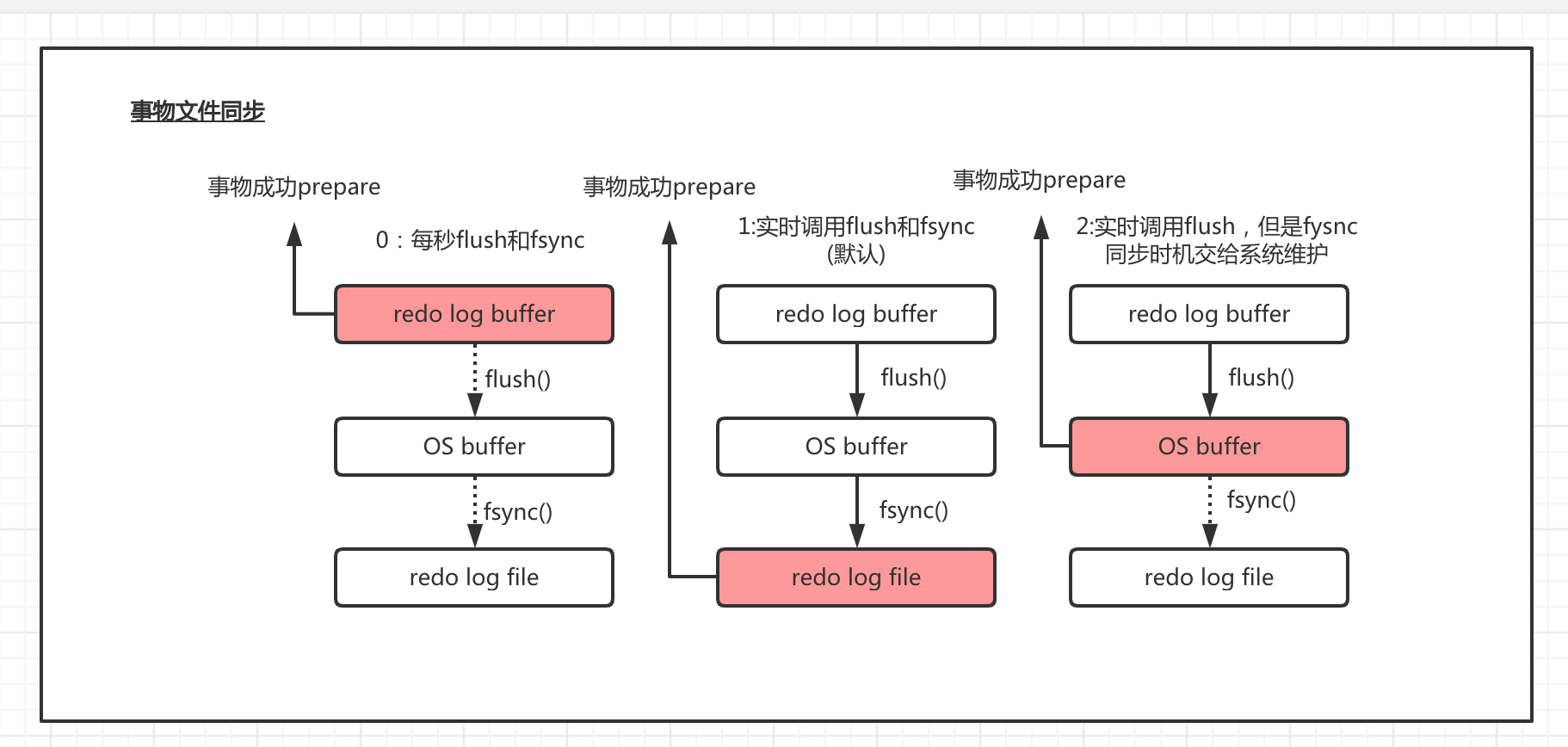
缓存同步磁盘的时机主要看这个配置:innodb_flush_log_at_trx_commit
0:每秒flush和fsync,定时器自己维护
1:实时调用flush和fsync(默认)
2: 实时调用flush,但是fysnc同步时机交给系统维护
在写入redo log file之后,我们知道buffer pool还需要将脏页进行刷盘,脏页刷到磁盘后,同步将redolog中的check pos往前移,即擦除redolog中的脏页。
check_pos后面到write_pos之间,表示已经刷过的数据(对应buffer pool干净页),check_pos用一个LSN(逻辑序列号)表示。
write_pos后面到check_pos之间,即新写入记录的数据(对应buffer pool脏页),write_pos也是用一个LSN(逻辑序列号)表示。
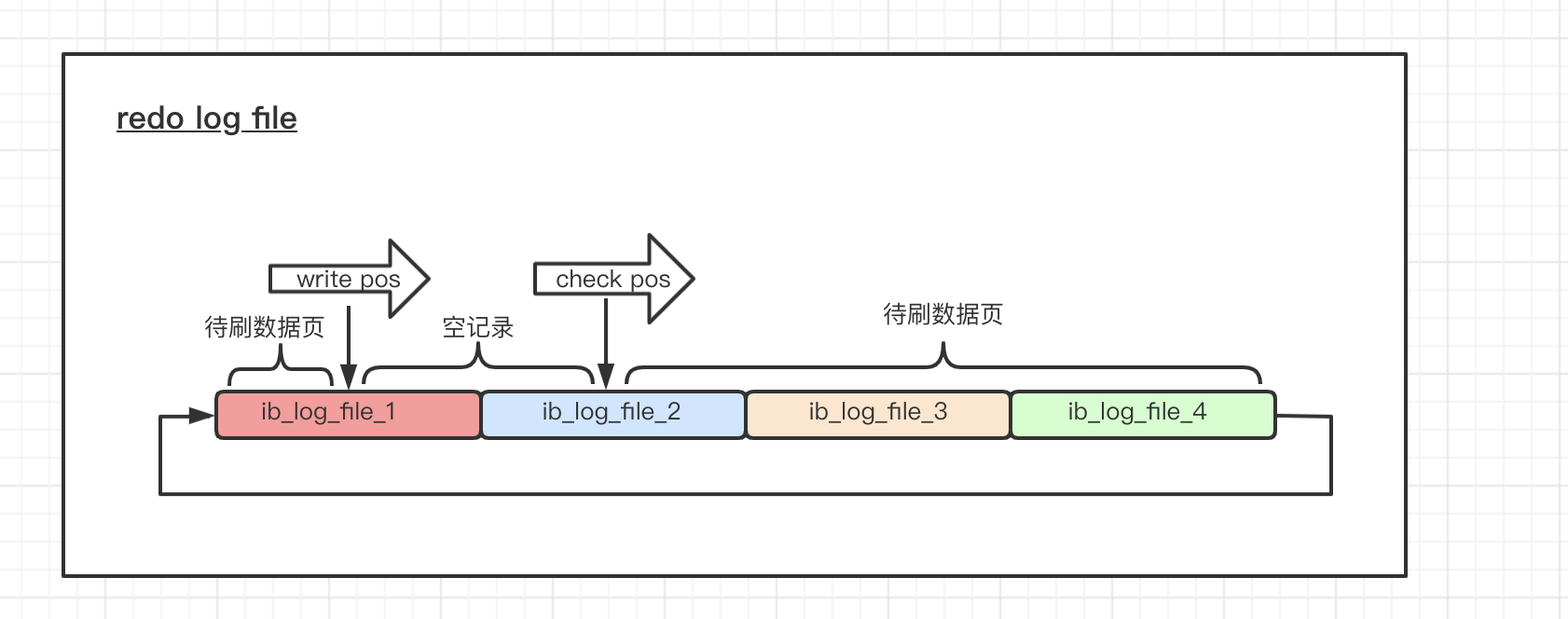
redo log 的作用:主要是在更新sql时,遇到断电情况,如果没有及时刷到磁盘数据页,但是事物又已经提交,就会丢掉buffer pool中,部分脏页(有修改的才是脏页),所以引入redo log来记录修改的信息,断电重启就可以根据redo log进行恢复,将待刷数据页(脏页),更新到内存中,以恢复之前因异常关闭而未保存的脏页。
2、undo log
用于保证未提交事件的原子性(Atomicity)
undo log的作用:用于存储事物修改前的数据信息,在例如提交发生异常时,用于回滚数据
3、MVCC
(Multi-Version Concurrency Control,多版本并发控制)和锁一起,保障隔离型(Isolation),在read committed和repeatable read隔离级别下实现事务A、事务B之间数据隔离,有关mysql的锁的知识参考这篇文章,这里摘一个图片
mvcc可以简单的理解为,开启事物(start transaction with consistentsnapshot)的时候会创建一个当前版本的「快照」,后面查询的时候,「可重复读」就在当前「快照」中查,「读已提交」就是每次执行查询都生成一个新的「快照」
MVCC的实现原理:
innoDB引擎存储数据的每一行row,都会有2个隐藏列,这两个字段关联undo log中的回滚记录
- 数据行的版本号 (DB_TRX_ID)
- 删除版本号 (DB_ROLL_PT)

快照是如何实现的呢?
查询的到最新的记录,如果发现记录中 DB_TRX_ID与当前事物DB_TRX_ID比较,不是历史事物,那么就要一直通过undolog回溯,找到第一个历史事物作为结果返回,这样就像是快照一样了。
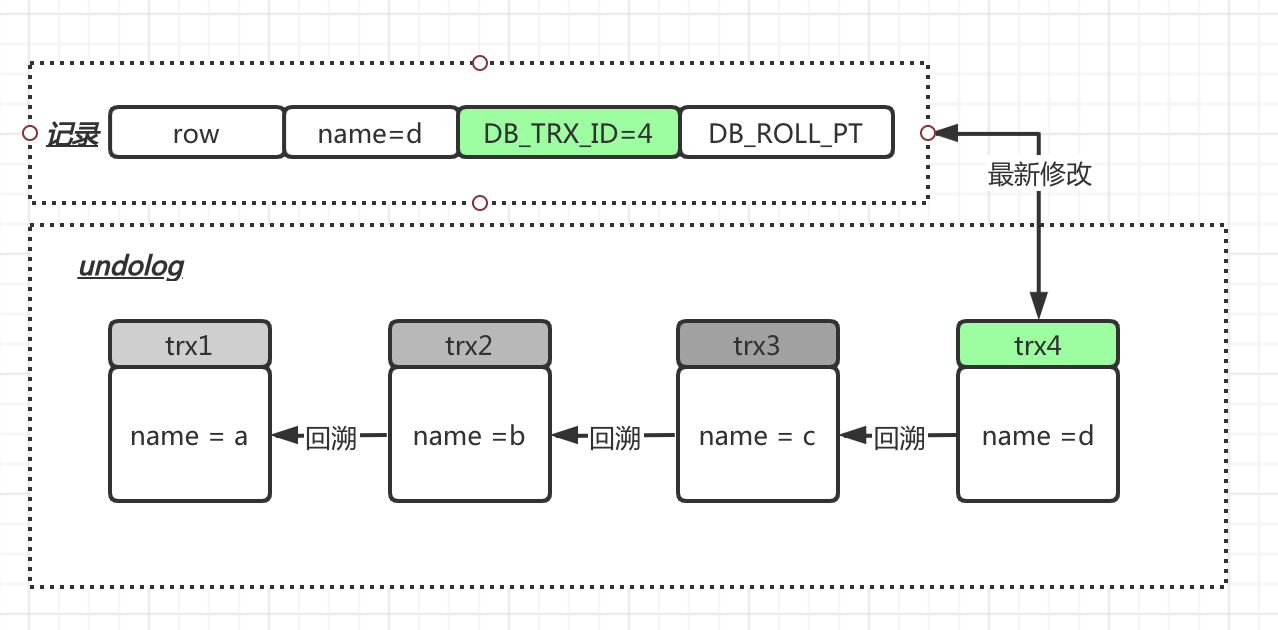
例如上图中,那么在trx4中修改位name=d了,那么trx1中,select查到的name 还是为a,是因为,trx1发现记录中的DB_TRX_ID=4,对于当前DB_TRX_ID=1来说不是历史事物,那么就需要通过undolog往回找,找到trx3,发现也不是历史事物,再如此往前找,直到找到trx1为止,即name=a返回。
如何判断找到否是历史事物呢?
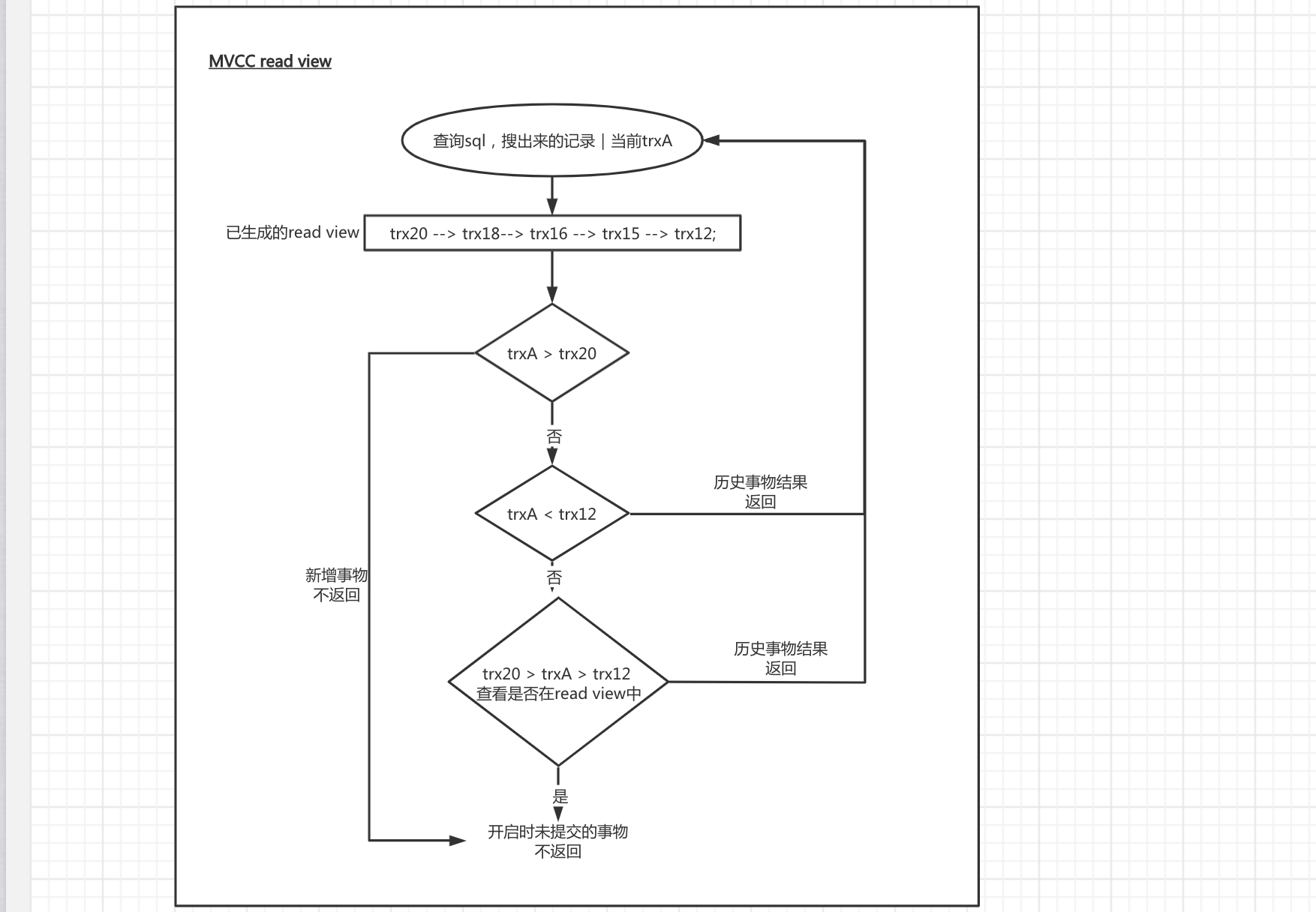
记录下当前所有活跃的事物版本号,生成一个trx数组的,这个视图数组,就组成了当前事务的一致性视图(read-view),然后在查询记录是,过滤不需要返回的记录:
- 1.trxId > trxMaxId,不返回,因为是新增的事物
- 2.trxId < trxMinId,返回,因为是历史的事物结果
- 3.trxMinId < trxId < trxMaxId,那么就看trxId是否在readview中,如果是,因为是在开启事物时,还未提交的事物,就不返回。否就因为是历史事物的结果,返回。